HDDScan
The program is designed to check hard drives and SSDs for bad sectors, view S.M.A.R.T. attributes, changing special settings, such as power management, spindle start/stop, acoustic mode adjustment, etc. The drive temperature value can be displayed in the taskbar.
Features and Requirements
Supported drive types:- HDD with ATA/SATA interface.
- HDD with SCSI interface.
- HDD with USB interface (see Appendix A).
- HDD with FireWire or IEEE 1394 interface (see Appendix A).
- RAID arrays with ATA/SATA/SCSI interface (tests only).
- Flash drives with USB interface (tests only).
- SSD with ATA/SATA interface.
- Test in linear verification mode.
- Test in linear reading mode.
- Test in linear recording mode.
- Butterfly reading mode test (artificial random reading test)
- Reading and analyzing S.M.A.R.T. parameters from disks with ATA/SATA/USB/FireWire interface.
- Reading and analyzing log tables from SCSI drives.
- Launch S.M.A.R.T. tests on drives with ATA/SATA/USB/FireWire interfaces.
- Temperature monitor for drives with ATA/SATA/USB/FireWire/SCSI interfaces.
- Reading and analysis of identification information from drives with ATA/SATA/USB/FireWire/SCSI interfaces.
- Changing AAM, APM, PM parameters on drives with ATA/SATA/USB/FireWire interfaces.
- View information about defects on a drive with a SCSI interface.
- Spindle start/stop on drives with ATA/SATA/USB/FireWire/SCSI interface.
- Saving reports in MHT format.
- Printing reports.
- Skin support.
- Command line support.
- Support for SSD drives.
- Operating system: Windows XP SP3, Windows Server 2003, Windows Vista, Windows 7, Windows 8, Windows 10 (NEW).
- The program should not be run from a drive operating in read-only mode.
User Interface
Main view of the program at startup
Rice. 1 Main type of program
Main window controls:
- Select Drive – a drop-down list that contains all supported drives in the system. The drive model and serial number are displayed. Nearby there is an icon that determines the expected type of drive.
- S.M.A.R.T. button – allows you to get a report on the state of the drive based on S.M.A.R.T attributes.
- TESTS button – displays a pop-up menu with a selection of read and write tests (see Figure 2).
- TOOLS Button – Displays a pop-up menu to select available drive controls and functions (see Figure 3).
- More button – shows a drop-down menu with program controls.
When you click the TESTS button, a pop-up menu offers you one of the tests. If you select any test, the test dialog box will open (see Figure 4).
Rice. 2 Test menu

When you press the TOOLS button, a pop-up menu will prompt you to choose from the following options:
Rice. 3 Function menu

- DRIVE ID – Generates an identification information report.
- FEATURES – opens a window of additional program features.
- S.M.A.R.T. TEST – opens the S.M.A.R.T window. tests: Short, Extended, Conveyance.
- TEMP MON – starts the temperature monitoring task.
- COMMAND – opens a command line build window.
Test Dialog Box
Rice. 4 Test dialog box
Controls:
- The FIRST SECTOR field is the initial logical number of the sector to be tested.
- Field SIZE – the number of logical sector numbers for testing.
- Field BLOCK SIZE – block size in sectors for testing.
- Previous button – returns to the main program window.
- Next button – adds a test to the task queue.
- Only one surface test can be run at a time. This is due to the fact that the author of the program has not yet been able to obtain stable, high-quality results when running 2 or more tests simultaneously (on different drives).
- A test in Verify mode can have a block size limit of 256, 16384 or 65536 sectors. This is due to the way Windows works.
- The test in Verify mode may not work correctly on USB/Flash drives.
- When testing in Verify mode, the drive reads a block of data into the internal buffer and checks its integrity; no data is transferred through the interface. The program measures the readiness time of the drive after performing this operation after each block and displays the results. Blocks are tested sequentially - from minimum to maximum.
- When testing in Read mode, the drive reads data into the internal buffer, after which the data is transferred through the interface and stored in the program's temporary buffer. The program measures the total time of drive readiness and data transfer after each block and displays the results. Blocks are tested sequentially - from minimum to maximum.
- When testing in Erase mode, the program prepares a block of data filled with a special pattern with a sector number and transfers the data to the drive, the drive writes the received block ( the information in the block is irretrievably lost!). The program measures the total time of block transmission and recording and drive readiness after each block and displays the results. Blocks are tested sequentially - from minimum to maximum.
- Testing in Butterfly Read mode is similar to testing in Read mode. The difference is in the order in which the blocks are tested. Blocks are processed in pairs. The first block in the first pair will be Block 0. The second block in the first pair will be Block N, where N is the last block of the given section. The next pair will be Block 1, Block N-1, etc. Testing ends in the middle of a given area. This test measures reading and positioning time.
Task management window
Rice. 5 Task manager

This window contains the task queue. This includes all the tests that the program runs, as well as the temperature monitor. The manager allows you to remove tests from the queue. Some tasks can be paused or stopped.
Double-clicking on an entry in the queue brings up a window with information about the current task.
Test information window
The window contains information about the test, allows you to pause or stop the test, and also generates a report.
Graph Tab:
Contains information on the dependence of testing speed on the block number, which is presented in the form of a graph.
Rice. 6 Graph Tab

Map Tab:
Contains information about the dependence of testing time on the block number, which is presented in the form of a map.
Rice. 7 Map tab

You can select Block Processing Time in milliseconds. Each tested block that took longer than the "Block Processing Time" will be logged in the "Report" tab.
Report tab:
Contains information about the test and all blocks whose testing time is greater than the “Block Processing Time”.
Rice. 8 Report tab
Identification information
The report contains information about the main physical and logical parameters of the drive.
The report can be printed and saved to an MHT file.
Rice. 9 Example of identification information window

S.M.A.R.T. report
The report contains information about the performance and health of the drive in the form of attributes. If, according to the program, the attribute is normal, then a green icon appears next to it. Yellow indicates attributes that you should pay special attention to; as a rule, they indicate some kind of drive malfunction. Red denotes attributes that are outside the norm.
Reports can be printed or saved to an MHT file.
Rice. 10 Example of a S.M.A.R.T. report

Temperature monitor
Allows you to evaluate the storage temperature. Information is displayed in the taskbar, as well as in a special test information window. Rice. 11 contains readings for two drives.
Rice. 11 Temperature monitor in the taskbar

For ATA/SATA/USB/FireWire drives, the information window contains 2 values. The second value is displayed in the taskbar.
The first value is taken from the Airflow Temperature attribute, the second value is taken from the HDA Temperature attribute.
Rice. 12 Temperature monitor for ATA/SATA disk

For SCSI drives, the information window contains 2 values. The second value is displayed in the taskbar.
The first value contains the maximum permissible temperature for the drive, the second shows the current temperature.
Rice. 13 Temperature monitor for SCSI disk

S.M.A.R.T. tests
The program allows you to run three types of S.M.A.R.T. tests:
- Short test – usually lasts 1-2 minutes. Checks the main components of the drive, and also scans a small area of the drive surface and sectors located in the Pending-List (sectors that may contain read errors). The test is recommended for quickly assessing the condition of the drive.
- Extended test – usually lasts from 0.5 to 60 hours. Checks the main components of the drive, and also completely scans the surface of the drive.
- Conveyance test – usually lasts several minutes. Checks drive nodes and logs, which may indicate improper storage or transportation of the drive.
A SMART test can be selected from the SMART Tests dialog box, which is accessed by clicking the SMART TESTS button.
Rice. 14 SMART Tests Dialog Box

Once selected, the test will be added to the Tasks queue. S.M.A.R.T information window test can display the execution and completion status of a task.
Rice. 15 Information window S.M.A.R.T. test

Additional features
For ATA/SATA/USB/FireWire drives, the program allows you to change some parameters.
- AAM – function controls drive noise. Enabling this function allows you to reduce drive noise due to smoother positioning of the heads. At the same time, the drive loses a little performance during random access.
- APM function allows you to save drive power by temporarily reducing the rotation speed (or completely stopping) the drive spindle during idle time.
- PM – function allows you to set the spindle stop timer for a specific time. When this time is reached, the spindle will be stopped, provided that the drive is in idle mode. Accessing the drive by any program forces the spindle to spin up and the timer is reset to zero.
- The program also allows you to force stop or start the drive spindle. Accessing the drive by any program forces the spindle to spin.
Rice. 16 Information window for additional ATA/SATA drive capabilities

For SCSI drives, the program allows you to view defect lists and start/stop the spindle.
Rice. 17 Information window for additional SCSI drive capabilities

Using the Command Line
The program can build a command line to control certain drive parameters and save this line to a .bat or .cmd file. When such a file is launched, the program is called in the background, changes the drive parameters according to the specified ones, and closes automatically.
Rice. 18 Command line build window

Appendix A: USB/FireWire Drives
If the drive is supported by the program, then tests are available for it, S.M.A.R.T. functions and additional features.
If the drive is not supported by the program, then only tests are available for it.
USB/FireWire drives supported by the program:
| Storage device | Controller chip |
| StarTeck IDECase35U2 | Cypress CY7C68001 |
| WD Passpopt | Unknown |
| Iomega PB-10391 | Unknown |
| Seagate ST9000U2 (PN: 9W3638-556) | Cypress CY7C68300B |
| Seagate External Drive (PN: 9W286D) | Cypress CY7C68300B |
| Seagate FreeAgentPro | Oxford |
| CASE SWEXX ST010 | Cypress AT2LP RC7 |
| Vantec CB-ISATAU2 (adapter) | JMicron JM20337 |
| Beyond Micro Mobile Disk 3.5" 120GB | Prolific PL3507 (USB only) |
| Maxtor Personal Storage 3100 | Prolific PL2507 |
| In-System ISD300A | |
| SunPlus SPIF215A | |
| Toshiba USB Mini Hard Drive | Unknown |
| USB Teac HD-15 PUK-B-S | Unknown |
| Transcend StoreJet 35 Ultra (TS1TSJ35U-EU) | Unknown |
| AGEStar FUBCP | JMicron JM20337 |
| USB Teac HD-15 PUK-B-S | Unknown |
| Prolific 2571 | |
| All Drives That Support SAT Protocol | Majority of Modern USB controllers |
USB/FireWire drives that the program may support:
| Storage device | Controller chip |
| AGEStar IUB3A | Cypress |
| AGEStar ICB3RA | Cypress |
| AGEStar IUB3A4 | Cypress |
| AGEStar IUB5A | Cypress |
| AGEStar IUB5P | Cypress |
| AGEStar IUB5S | Cypress |
| AGEStar NUB3AR | Cypress |
| AGEStar IBP2A2 | Cypress |
| AGEStar SCB3AH | JMicron JM2033x |
| AGEStar SCB3AHR | JMicron JM2033x |
| AGEStar CCB3A | JMicron JM2033x |
| AGEStar CCB3AT | JMicron JM2033x |
| AGEStar IUB2A3 | JMicron JM2033x |
| AGEStar SCBP | JMicron JM2033x |
| AGEStar FUBCP | JMicron JM2033x |
| Noontec SU25 | Prolific PL2507 |
| Transcend TS80GHDC2 | Prolific PL2507 |
| Transcend TS40GHDC2 | Prolific PL2507 |
| I-O Data HDP-U series | Unknown |
| I-O Data HDC-U series | Unknown |
| Enermax Vanguard EB206U-B | Unknown |
| Thermaltake Max4 A2295 | Unknown |
| Spire GigaPod SP222 | Unknown |
| Cooler Master - RX-3SB | Unknown |
| MegaDrive200 | Unknown |
| RaidSonic Icy Box IB-250U | Unknown |
| Logitech USB | Unknown |
USB/FireWire drives that the program does not support:
| Storage device | Controller chip |
| Matrix | Genesis Logic GL811E |
| Pine | Genesis Logic GL811E |
| Iomega LDHD250-U | Cypress CY7C68300A |
| Iomega DHD160-U | Prolific PL-2507 (modified firmware) |
| Iomega | |
| Maxtor Personal Storage 3200 | Prolific PL-3507 (modified firmware) |
| Maxtor One-Touch | Cypress CY7C68013 |
| Seagate External Drive (PN-9W2063) | Cypress CY7C68013 |
| Seagate Pocket HDD | Unknown |
| SympleTech SympleDrive 9000-40479-002 | CY7C68300A |
| Myson Century CS8818 | |
| Myson Century CS8813 |
Appendix B: SSD drives
Support for a particular drive largely depends on the controller installed on it.
SSD drives supported by the program:
| Storage device | Controller chip |
| OCZ Vertex, Vertex Turbo, Agility, Solid 2 | Indilinx IDX110M00 |
| Super Talent STT_FTM28GX25H | Indilinx IDX110M00 |
| Corsair Extreme Series | Indilinx IDX110M00 |
| Kingston SSDNow M-Series | Intel PC29AS21AA0 G1 |
| Intel X25-M G2 | Intel PC29AS21BA0 G2 |
| OCZ Throttle | JMicron JMF601 |
| Corsair Performance Series | Samsung S3C29RBB01 |
| Samsung SSDs | Samsung Controllers |
| Crucial and Micron SSDs | Some Marvel Controllers |
SSD drives that the program may support:
Additional Information
Version HDDScan 3.3 can be downloaded version 2.8
| Support: |
Modern hard drives are quite “smart” devices and, in addition to the basic properties inherent in them as data storage and processing devices, they support the technology of self-testing, state analysis, and accumulation of statistical data on the deterioration of their own characteristics S.M.A.R.T. (S elf- M monitoring A nalysis a nd R exporting T echnology). Basics of S.M.A.R.T. were developed in 1995 by joint efforts of leading hard drive (HDD) manufacturers. In subsequent years, S.M.A.R.T standards were refined in accordance with changes in technology and equipment (SMART II and SMART III) and continue to be improved at the present time.
The hard drive, starting from the moment of its manufacture, constantly monitors certain parameters of its condition and reflects them in special characteristics - attributes(Attribute) stored in a permanent storage device, as a rule, in a specially allocated part of the disk surface, accessible only to the internal firmware of the drive - service area. Attribute data can be read according to the ATA specification ( AT A ttachment) using SMART support commands (SMART READ DATA and more than a dozen commands), which are transmitted to the drive by special software, such as utilities from equipment manufacturers or universal programs for testing and monitoring HDD status (udisks, smartctl, GSmartControl, gnome-disks and so on.). Modern ATA standards include support for the SCT (SMART Command Transport) protocol, which provides reading of device statistics logs. The device statistics log is a read-only SMART log sent by the drive when it receives a READ LOG EXT, READ LOG DMA EXT, or SMART READ LOG command.
The attribute is a characteristic of a certain state of the hard drive, which changes during operation, taking a numerical value from the maximum set at the time of manufacture of this device to the minimum, upon reaching which the operability of the drive is not guaranteed. All attributes are identified by their numeric number, most of which are interpreted the same by hard drives of different models. Some of them can only be used by a specific hardware manufacturer and supported by certain drive models. So, for example, an attribute with an identifier 7 , characterizing the number of errors in installing heads on the required track of the disk surface Seek_Error_Rate does not make sense for solid state drives (SSD) and, accordingly, is not supported by them, and the attribute with the identifier 9 , which characterizes the total operating time of the drive over its entire service life and is denoted as Power_On_Hours,Supported by both SSD and traditional HDD.
Attributes consist of several fields (most often denoted as Val, Worst, Tresh, RAW), each of which is a specific indicator characterizing the technical condition of the drive at a given time. S.M.A.R.T. Reader Programs display the contents of attributes, usually in the form of several columns:
Pre-Failure (PF, 01h)- when the threshold value of this attribute type is reached, the disk requires replacement. Sometimes this flag bit is denoted as Life Critical (CR) or Pre-Failure warranty (PW)
O nline test (OC, 02h) – the attribute updates the value when running off-line/on-line built-in SMART tests;
P erfomance R elated (PE or PR, 04h) – the attribute characterizes performance;
E rror R ate (ER, 08h) – the attribute reflects equipment error counters;
E vent C ounts (EC, 10h) – the attribute represents an event counter;
S elf P reserving (SP, 20h) – self-preserving attribute;
Some of the programs can interpret flags in the form of text descriptions, similar in meaning to those discussed above. One attribute can have several flag values set to one, for example, an attribute with an identifier 05
reflecting the number of sectors reassigned due to failures from the reserve area, has the SP+EC+OC flags set - self-preserving, event counter, updated when the drive is in offline and interactive mode.
To analyze the state of the drive, perhaps the most important attribute value is Value- a conditional number (usually from 0 to 100 or up to 253) specified by the manufacturer. Meaning Value initially set to maximum when the drive is manufactured and decreases if its parameters deteriorate. For each attribute there is a threshold value, upon reaching which the manufacturer does not guarantee its performance - field Threshold. If the value Value approaches or becomes less than the value Threshold, - it’s time to change the drive.
The list of attributes and their meanings are not strictly standardized and some of them can be determined by the drive manufacturer, but the main part is interpreted the same. For example, an attribute with an id 05 (Reallocated sector count) will characterize the number of disk sectors rejected and reassigned from the reserve area, both for devices manufactured by Seagate Technology and for devices manufactured by Western Digital. The set of supported attributes depends on the drive model and may vary significantly in composition for different models.
The most common software tool for obtaining S.M.A.R.T data in the Linux environment is the utility smartctl from the kit smartmontools, as a rule, included in the default installed software of any distribution. If necessary, you can update the version and download documentation in English on the project website smartmontools.org.
To work with the utility smartctl superuser rights required root.
Command Line Format smartctl:
smartctl device parameters
Examples of using smartctl
smartctl –help or smartctl --usage- display a hint about using the command.
Options smartctl:
-V, --version, --copyright, --license- display version, copyright and license information.
-i, --info- display identification information for the device.
-g NAME, --get=NAME- display disk settings parameters (all, aam, apm, lookahead, security, wcache, rcache, wcreorder)
-a, --all- display all SMART data of the specified drive.
-x, --xall- display all technical data for the specified disk.
--scan- search for disk devices.
-q TYPE, --quietmode=TYPE set output granularity mode for smartctl (errorsonly, silent, noserial)
-d TYPE, --device=TYPE- set the device type (ata, scsi, sat[,auto][,N][+TYPE], usbcypress[,X], usbjmicron[,p][,x][,N], usbsunplus, marvell, areca,N /E, 3ware,N, hpt,L/M/N, megaraid,N, cciss,N, auto, test) Typically, setting the device type is required in cases where the utility smartctl cannot detect it automatically.
-b TYPE, --badsum=TYPE- set the reaction to detection of checksum errors (warn, exit, ignore)
-r TYPE, --report=TYPE- the option is intended for developers smartmontools and allows you to obtain detailed information when performing transactions of the I/O device management function ioctl(ioctl, ataioctl, scsiioctl and debug level). Details - man smartctl
-n MODE, --nocheck=MODE- prohibition mode for running tests for energy saving modes (never, sleep, standby, idle). Typically used to prevent the spindle motor from starting on a smartctl command.
-s VALUE, --smart=VALUE- disable or enable SMART (on/off)
-o VALUE, --offlineauto=VALUE- prohibition or permission of automatic execution of tests in non-interactive mode (in drive idle mode), accepted values - on/off
-S VALUE, --saveauto=VALUE autosave attributes (on/off)
-s NAME[,VALUE], --set=NAME[,VALUE]- prohibit/enable drive hardware parameters (aam,, apm,, lookahead,, security-freeze, standby,, wcache,, rcache,, wcreorder,)
-H, --health- display the drive status (SMART health status)
-c, --capabilities- display information about the supported SMART capabilities of the specified hard drive.
-A, --attributes- display SMART attributes
-f FORMAT, --format=FORMAT- set the format of the displayed SMART attributes (old, brief, hex[,id|val]). Mainly affects the format of the displayed values of attribute identifiers and the format of display of their flags:
old- attribute identifiers are displayed in decimal notation, flag values are displayed in hexadecimal and interpreted as text.
hex- the same as in the previous case, but attribute identifiers are displayed in hexadecimal notation.
brief- compact output, identifiers are displayed in decimal notation, flags are displayed as symbols with explanations at the bottom of the table:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE 1 Raw_Read_Error_Rate POSR-- 114 100 006 - 78309029 . . . . . . 254 Free_Fall_Sensor -O--CK 100 100 000 - 0 ||||||_ K auto-keep |||||__ C event count ||||___ R error rate |||____ S speed/performance || _____ O updated online |______ P prefailure warning
-l TYPE, --log=TYPE- display the specified device log (selftest, selective, directory[,g|s], xerror[,N][,error], xselftest[,N][,selftest],background, sasphy[,reset], sataphy[,reset ], scttemp, scttempint,N[,p], scterc[,N,M], devstat[,N], ssd, gplog,N[,RANGE], smartlog,N[,RANGE]
-v N,OPTION , --vendorattribute=N,OPTION- set a parameter for a manufacturer-defined attribute with identifier N
-F TYPE, --firmwarebug=TYPE- adaptation of the program to account for errors in the drive’s hardware firmware (none, nologdir, samsung, samsung2, samsung3, xerrorlba, swapid)
-P TYPE, --presets=TYPE- preset disk parameters. By default, having detected information about the drive in its database, the utility smartctl, uses the set of parameters available for a given model. Option use- use presets for this drive, ignore- do not use, show- display presets for this disc, showall- display presets for the specified model. Examples:
smartctl –P ignore /dev/hdb- ignore presets for disk /dev/hdb;
smartctl –P show /dev/sdb- display presets for the specified disk;
smartctl –P showall ‘ST9250315AS’- - display presets for the specified disk model - ST9250315AS;
smartctl –P showall ‘ST3750515AS’ ‘SD15’- display presets for the specified disk model ST3750515AS with SD15 firmware;
-B [+]FILE, --drivedb=[+]FILE- read and change the disk model database from the FILE file. The “+” sign before the file name means adding new records to the database, before existing ones.
By default, the database is stored in the file /usr/share/smartmontools/drivedb.h
DEVICE SELF-TEST OPTIONS =====
-t TEST, --test=TEST- run the test TEST Run test. TEST: offline, short, long, conveyance, force, vendor,N, select,M-N, pending,N, afterselect,
-C, --captive- performing tests in drive capture mode. Used in conjunction with the parameter -t for tests Not in mode offline. Using this option may cause the device to be busy for the duration of the test and may result in system disruption and data loss. You should not use the option -c to perform tests on drives with mounted partitions. For SCSI devices, this option means running built-in tests in the "Foreground mode".
-X, --abort- force completion of a test running without a key --captive.
Examples of using smartctrl.
smartctl --info /dev/sdb- display identification information for device /dev/sdb. Example command output:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:31 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled
smartctl --all /dev/hda- display all SMART data for the device /dev/hda
Example of displayed data:
=== START OF INFORMATION SECTION === Device Model: ST9500620NS Serial Number: 9XF0AW8T Firmware Version: SN01 User Capacity: 500,107,862,016 bytes Device is: Not in smartctl database ATA Version is: 8 ATA Standard is: ATA-8-ACS revision 4 Local Time is: Tue Oct 28 15:05:45 2014 MSK SMART support is: Available - device has SMART capability. SMART support is: Enabled === START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED General SMART Values: Offline data collection status: (0x82) Offline data collection activity was completed without error. Auto Offline Data Collection: Enabled. Self-test execution status: (0) The previous self-test routine completed without error or no self-test has ever been run. Total time to complete Offline data collection: (634) seconds. Offline data collection capabilities: (0x7b) SMART execute Offline immediate. Auto Offline data collection on/off support. Suspend Offline collection upon new command. Offline surface scan supported. Self-test supported. Conveyance Self-test supported. Selective Self-test supported. SMART capabilities: (0x0003) Saves SMART data before entering power-saving mode. Supports SMART auto save timer. Error logging capability: (0x01) Error logging supported. General Purpose Logging supported. Short self-test routine recommended polling time: (1) minutes. Extended self-test routine recommended polling time: (102) minutes. Conveyance self-test routine recommended polling time: (2) minutes. SCT capabilities: (0x10bd) SCT Status supported. SCT Feature Control supported. SCT Data Table supported. SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 082 064 044 Pre-fail Always - 190274202 3 Spin _Up_Time 0x0003 096 096 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 72 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 070 060 030 Pre-fail Always - 11302732 9 Power_On _Hours 0x0032 073 073 000 Old_age Always - 24037 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 72 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 100 100 000 Old_age Always - 0 188 Command_Timeout 0x0032 100 100 000 Old_age Always - 0 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 081 048 045 Old_age Always - 19 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 38 193 Load_Cycle_Count 0x0032 100 100 000 Old_age Always - 73 194 Temperature_Celsius 0x0022 019 052 000 Old_age Always - 19 (0 14 0 0) 195 Hardware_ECC_Recovered 0x001a 118 100 000 Old_age Always - 190274202 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 0 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 SMART Error Log Version: 1 No Errors Logged SMART Self-test log structure revision number 1 No self-tests have been logged. SMART Selective self-test log data structure revision number 1 SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS 1 0 0 Not_testing 2 0 0 Not_testing 3 0 0 Not_testing 4 0 0 Not_testing 5 0 0 Not_testing Selective self-test flags (0x0): After scanning selected spans, do NOT read-scan remainder of disk. If Selective self-test is pending on power-up, resume after 0 minute delay.
smartctl -A -v 9,minutes /dev/hda- display all SMART attribute data for the device /dev/hda and an attribute with an identifier 9 (on time) interpreted as an internal value specified in minutes rather than hours.
smartctl --smart=on --offlineauto=on --saveauto=on /dev/hda- enable SMART for the /dev/hda drive, allow automatic execution of offline tests and self-saving of attributes. The command can be executed on a running system. In fact, this is setting standard operating parameters for a regular disk drive.
smartctl --test=long /dev/hda- run extended built-in tests for the /dev/hda disk. The command can be used on a running system. To view the results of running tests, use the command to output internal log after test completion
smartctl -l selftest /dev/hda
smartctl --attributes --log=selftest --quietmode=errorsonly /dev/had- display internal self-test log data and error attributes.
smartctl -s on -t offline /dev/hdc- enable SMART and perform an offline test for the /dev/hdc drive. If an error is detected during testing, information about it will be recorded in an internal log, which can be viewed using the parameter -l error.
smartctl -q silent -a /dev/had- check SMART data without displaying the received information. Usually used in scripts. After executing the command, the return code is checked (variable $? command shell) to determine whether the value of any attribute exceeds the limit value or whether there is an error record in the device logs.
smartctl -q errorsonly -H -l selftest /dev/had- display information only if there is an erroneous SMART status or if any of the internal tests fail.
smartctl -t select,10-100 -t select,30-300 -t afterselect,on -t pending,45 /dev/hda- perform an internal test in a specified area of LBA blocks and, after its completion, scan the rest of the disk. If the power is turned off during scanning, continue it 45 minutes after turning it on.
smartctl --all --device=3ware,0 /dev/sda- get SMART data for the first ATA disk connected to the 3ware RAID controller.
smartctl -a -d 3ware,0 /dev/twe0- get SMART data for the first ATA disk connected to the 3ware RAID 6000/7000/8000 RAID controller.
smartctl -a -d 3ware,0 /dev/twa0- get SMART data for the first ATA disk connected to the 3ware RAID 9000 RAID controller
smartctl -t short -d 3ware,3 /dev/sdb- run short internal tests for the 4th disk, the second SCSI disk device /dev/sdb
smartctl -a -d hpt,1/3 /dev/sda- obtain SMART data of the disk connected to the 3rd channel of the first HighPoint RocketRAID controller
Decoding S.M.A.R.T attributes
Attribute identifiers are indicated in the decimal number system, and in brackets they are indicated in hexadecimal.
Assessment of the technical condition of the hard drive according to S.M.A.R.T data
The set of attributes supported by a specific hard drive model, even if it is minimal, allows you to determine with high reliability the technical condition and prospects for the operation of the device. You can determine the time spent in the on state by the attribute value 9 , and in combination with the attribute value 12 - the number of power supply on/offs, and therefore - round-the-clock or periodic operation mode. Intensity of use, temperature conditions, negative external influences - all these facts are easily tracked using the absolute values of the corresponding attributes. In the same way, you can evaluate the level of equipment wear, the quality of the surface and the write/read path.
Minimal informative monitoring of disk status can be performed even at the BIOS level. If any attribute that characterizes performance reaches a critical value when S.M.A.R.T status monitoring is enabled in the BIOS settings, loading of the operating system is suspended and the following message is displayed on the screen:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Press F1 to Resume
Thus, without installing or launching additional software, it is possible to timely determine the critical state of the drive using the Basic Input-Output System (BIOS) when turning on the computer.
The technical condition of a hard drive that has not reached a critical threshold is characterized by the absolute value of attributes reflecting counters of failures detected and corrected by the drive hardware.
Changes in the absolute values of attributes must be considered in dynamics, and in a logical relationship with each other.
Run built-in S.M.A.R.T tests
The set of built-in S.M.A.R.T tests is determined by the manufacturer and can vary significantly for different hard drive models. Basically, the built-in SMART tests are represented by short tests (short self-test) and long ones (extended sels-test). Short tests scan a small portion of the disk surface, defined by the manufacturer, and run on average in about 1 minute. Long tests scan the entire working surface of the disk and can take several hours, depending on the speed and size of the disk. Also, for modern drives, you can perform selective tests (selective self-test), the parameters of which are specified by the user, and tests after transporting the device (conveyance self-test). Tests can be aborted if the drive's capture mode is not set (captive) and the drive supports the test abort command. Regarding the drive capture mode when performing tests captive, then you need to use it carefully if the disk is being used by the system.
Examples:
smartctl --test=short /dev/sdb- run a short test. In response to the command, the following information will be displayed:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Short self-test routine immediately in off-line mode." Drive command "Execute SMART Short self-test routine immediately in off-line mode" successful. Testing has begun (previous test aborted). Please wait 1 minutes for test to complete. Test will complete after Fri Dec 5 16:08:09 2014 Use smartctl -X to abort test.
Which means that a command was sent to the disk to perform a short test, the disk received it successfully, the test will last 1 minute, and to force it to terminate, you can use the smartctl –X command.
The result of the test can be checked by viewing the test log with the command smartctl –l selftest. Log information will be received in response selftest:
=== START OF READ SMART DATA SECTION === SMART Self-test log structure revision number 1 Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error # 1 Short offline Completed without error 00% 831 -
Journal columns: Num- record number.
Test_Description- description of the test.
Status- completion status (completed without errors)
Remaining- percentage of time remaining until the test is completed, if it is not yet completed (00%)
LifeTime(hours)- operating time of the drive from the start of operation.
LBA_of_first_error- number of the LBA logical block where the first error was detected during test execution. In this example, there are no errors.
To run a long test, use the command:
smartctl --test=long /dev/sdb
In response to the command, information about the start of the test is displayed:
=== START OF OFFLINE IMMEDIATE AND SELF-TEST SECTION === Sending command: "Execute SMART Extended self-test routine immediately in off-line mode." Drive command "Execute SMART Extended self-test routine immediately in off-line mode" successful. Testing has begun. Please wait 70 minutes for test to complete. Test will complete after Fri Dec 5 17:15:44 2014
As you can see, the long test for this drive model will take 70 minutes.
The execution result can be checked with the command smartctl –l selftest /dev/sda
List of ATA commands for working with S.M.A.R.T
SMART_READ_VALUES 0xd0 SMART_READ_THRESHOLDS 0xd1 SMART_AUTOSAVE 0xd2 SMART_SAVE 0xd3 SMART_IMMEDIATE_OFFLINE 0xd4 SMART_READ_LOG_SECTOR 0xd5 SMART_WRITE_LOG_SECTOR 0xd6 SMART_ENABLE 0xd8 SMART_DISABLE 0xd9 SMART_STATUS 0xda SMART_AUTO_OFFLINE 0xdb
Additional information on hardware in Linux:
Sooner or later (it’s better, of course, if early) any user asks himself the question of how long the hard drive installed on his computer will last and whether it’s time to look for a replacement. There is nothing surprising in this, since hard drives, due to their design features, are the least reliable among computer components. At the same time, it is on the HDD that most users store the lion's share of a wide variety of information: documents, pictures, various software, etc., as a result of which an unexpected failure of the disk is always a tragedy. Of course, it is often possible to restore information on apparently “dead” hard drives, but it is possible that this operation will cost you a pretty penny, and will cost you a lot of nerves. Therefore, it is much more effective to try to prevent data loss.
How? It’s very simple... Firstly, do not forget about regular data backups, and secondly, monitor the condition of the disks using specialized utilities. We will consider several programs of this kind from the perspective of the tasks being solved in this article.
Control of SMART parameters and temperature
All modern HDDs and even solid state drives (SSDs) support S.M.A.R.T technology. ( from English Self-Monitoring, Analysis, and Reporting Technology (self-monitoring, analysis and reporting technology), which was developed by major hard drive manufacturers to increase the reliability of their products. This technology is based on continuous monitoring and assessment of the condition of the hard drive using built-in self-diagnosis equipment (special sensors), and its main purpose is the timely detection of possible drive failure.
Real-time HDD status monitoring
A number of information and diagnostic solutions for diagnosing and testing hardware, as well as special monitoring utilities, use S.M.A.R.T technology. to monitor the current status of various vital parameters that describe the reliability and performance of hard drives. They read the relevant parameters directly from the sensors and thermal sensors that all modern hard drives are equipped with, analyze the received data and display them in the form of a short tabular report with a list of attributes. At the same time, some utilities (Hard Drive Inspector, HDDlife, Crystal Disk Info, etc.) are not limited to displaying a table of attributes (the meanings of which are incomprehensible to untrained users) and additionally display brief information about the state of the disk in a more understandable form.
Diagnosing the condition of a hard drive using this kind of utility is as easy as shelling pears - just read the brief basic information about installed HDDs: basic data about drives in Hard Drive Inspector, a certain conditional percentage of hard drive health in HDDlife, and the “Technical Condition” indicator in Crystal Disk Info ( Fig. 1), etc. Any of these programs provides the minimum necessary information about each of the HDDs installed on the computer: data about the hard drive model, its volume, operating temperature, operating time, as well as the level of reliability and performance. This information makes it possible to draw certain conclusions about the performance of the media.
Rice. 1. Brief information about the “health” of the working HDD
You should configure the monitoring utility to launch simultaneously with the start of the operating system, adjust the time interval between checks of S.M.A.R.T. attributes, and also enable the display of the temperature and “health level” of hard drives in the system tray. After this, to monitor the status of the disks, the user will only need to glance from time to time at the indicator in the system tray, where brief information about the state of the drives available in the system will be displayed: their “health” level and temperature (Fig. 2). By the way, operating temperature is no less important an indicator than a conditional indicator of the health of the HDD, because hard drives can suddenly fail due to simple overheating. Therefore, if the hard drive heats up above 50 °C, then it would be wiser to provide it with additional cooling.

Rice. 2.Display HDD Status
in the system tray with the HDDlife program
It is worth noting that a number of such utilities provide integration with Windows Explorer, due to which a green icon is displayed on the icons of local drives if they are working properly, and if problems arise, the icon turns red. So you are unlikely to forget about the health of your hard drives. With such constant monitoring, you will not be able to miss the moment when some problems begin to arise with the disk, because if the utility detects critical changes in S.M.A.R.T. attributes. and/or temperature, it will carefully notify the user about this (with a message on the screen, a sound message, etc. - Fig. 3). Thanks to this, it will be possible to copy data from the dangerous media in advance.

Rice. 3. Example of a message about the need to immediately replace the disk
Using S.M.A.R.T. monitoring solutions in practice to monitor the status of hard drives is completely easy, because all such utilities work in the background and require a minimum of hardware resources, so their functioning will in no way interfere with the main workflow.
Control of S.M.A.R.T. attributes
Advanced users, of course, are unlikely to limit themselves to assessing the condition of hard drives by viewing a brief verdict from one of the utilities presented above. This is understandable, because according to the decoding of the S.M.A.R.T. attributes. You can identify the cause of failures and, if necessary, take precautionary measures. True, to independently control S.M.A.R.T. attributes, you will need to at least briefly become familiar with S.M.A.R.T technology.
Hard drives that support this technology include intelligent self-diagnostic procedures so they can “report” their current status. This diagnostic information is provided as a collection of attributes, that is, specific characteristics of the hard drive used to analyze its performance and reliability.
B O Most of the important attributes have the same meaning for drives from all manufacturers. The values of these attributes during normal disk operation may vary within certain intervals. For any parameter, the manufacturer has determined a certain minimum safe value that cannot be exceeded under normal operating conditions. Unambiguously determine critically important and critically unimportant S.M.A.R.T parameters for diagnostics. problematic. Each of the attributes has its own information value and indicates one or another aspect of the work of the medium. However, first of all you should pay attention to the following attributes:
- Raw Read Error Rate - the frequency of errors in reading data from the disk caused by the fault of the equipment;
- Spin Up Time - average spin-up time of the disk spindle;
- Reallocated Sector Count - number of sector reassignment operations;
- Seek Error Rate - frequency of occurrence of positioning errors;
- Spin Retry Count - the number of repeated attempts to spin up disks to operating speed if the first attempt fails;
- Current Pending Sector Count - the number of unstable sectors (that is, sectors awaiting the reassignment procedure);
- Offline Scan Uncorrectable Count - the total number of uncorrected errors during sector read/write operations.
Typically S.M.A.R.T. attributes are displayed in tabular form indicating the attribute name (Attribute), its identifier (ID) and three values: current (Value), minimum threshold (Threshold) and the lowest attribute value for the entire operating time of the drive (Worst), as well as the absolute value of the attribute (Raw). Each attribute has a current value, which can be any number from 1 to 100, 200, or 253 (there are no general standards for upper bounds on attribute values). The Value and Worst values for a completely new hard drive are the same (Fig. 4).

Rice. 4. Attributes of S.M.A.R.T. with a new HDD
Shown in Fig. 4 information allows us to conclude that for a theoretically serviceable hard drive, the current (Value) and worst (Worst) values should be as close as possible to each other, and the Raw value for most parameters (with the exception of the parameters: Power-On Time, HDA Temperature and some others ) should approach zero. The current value may change over time, which in most cases reflects deterioration of the hard drive parameters described by the attribute. This can be seen in Fig. 5, which presents fragments of the S.M.A.R.T attribute table. for the same disk - data were obtained with an interval of six months. As you can see, in the more recent version of S.M.A.R.T. the frequency of errors when reading data from the disk (Raw Read Error Rate), the origin of which is determined by the hardware of the disk, and the frequency of errors when positioning the magnetic head unit (Seek Error Rate) have increased, which may indicate overheating of the hard drive and its unstable position in the basket . If the current value of any attribute approaches or becomes less than the threshold value, then the hard drive is considered unreliable and should be replaced urgently. For example, a drop in the value of the Spin-Up Time attribute (average spin-up time of the disk spindle) below a critical value, as a rule, indicates complete wear of the mechanics, as a result of which the disk is no longer able to maintain the rotation speed specified by the manufacturer. Therefore, it is necessary to monitor the condition of the HDD and periodically (for example, once every 2-3 months) carry out S.M.A.R.T diagnostics. and save the received information in a text file. In the future, these data can be compared with current ones and certain conclusions can be drawn about the development of the situation.

Rice. 5. S.M.A.R.T. attribute tables obtained at six-month intervals
(more recent version of S.M.A.R.T. below)
When viewing S.M.A.R.T. attributes, you should first of all pay attention to critical parameters, as well as parameters highlighted by indicators other than the base color (usually blue or green). Depending on the current state of the attribute in the S.M.A.R.T. utility output. in the table it is usually marked in one color or another, which makes it easier to understand the situation. In particular, in the Hard Drive Inspector program, the color indicator can have green, yellow-green, yellow, orange or red - green and yellow-green colors indicate that everything is normal (the attribute value has not changed or changed insignificantly), and yellow, orange and red colors signal danger (the worst color is red, which indicates that the attribute value has reached its critical value). If any of the critical parameters are marked with a red icon, then you need to urgently replace the hard drive.
In the Hard Drive Inspector program, let's look at the table of S.M.A.R.T. attributes of the same drive, which we briefly assessed using monitoring utilities earlier. From Fig. 6 it can be seen that the values of all attributes are normal and all parameters are marked in green. The HDDlife and Crystal Disk Info utilities will show a similar picture. True, more professional solutions for analyzing and diagnosing HDDs are not so loyal and often mark S.M.A.R.T. attributes more meticulously. For example, such well-known utilities as HD Tune Pro and HDD Scan, in our case, were suspicious of the UltraDMA CRC Errors attribute, which displays the number of errors that occur when transmitting information over the external interface (Fig. 7). The cause of such errors is usually associated with a twisted and poor-quality SATA cable, which may need to be replaced.

Rice. 6. Table of S.M.A.R.T. attributes obtained in the Hard Drive Inspector program

Rice. 7. Results of assessing the state of S.M.A.R.T. attributes
HD Tune Pro and HDD Scan utilities
For comparison, let’s take a look at the S.M.A.R.T. attributes of a very ancient, but still working HDD with periodically arising problems. It did not inspire confidence in the Crystal Disk Info program - in the “Technical Condition” indicator, the disk condition was rated as alarming, and the Reallocated Sector Count attribute was highlighted in yellow (Fig. 8). This is a very important attribute from the point of view of the “health” of the disk, indicating the number of sectors reassigned when the disk detects a read/write error; during this operation, data from the damaged sector is transferred to the reserve area. The yellow color of the indicator for the parameter indicates that there are few remaining spare sectors with which to replace the bad ones, and soon there will be nothing to reassign the newly appearing bad sectors. Let's also check how more serious solutions assess the condition of the disk, for example, the HDDScan utility widely used by professionals - but here we see exactly the same result (Fig. 9).

Rice. 8. Assessing a problematic hard drive in CrystalDiskInfo

Rice. 9. Results of S.M.A.R.T. diagnostics of HDD in HDDScan
This means that it’s clearly not worth delaying the replacement of such a hard drive, although it may still serve for some time, although, of course, you cannot install an operating system on this hard drive. It is worth noting that if there are a large number of reassigned sectors, the read/write speed drops (due to the unnecessary movements that the magnetic head has to make), and the disk begins to noticeably slow down.
Scanning the surface for bad sectors
Unfortunately, in practice, monitoring SMART parameters and temperature alone is not enough. If the slightest evidence appears that something is wrong with the disk (in the case of periodic program freezes, for example, when saving results, reading error messages appear, etc.), it is necessary to scan the disk surface for the presence of unreadable sectors. To carry out such a media check, you can use, for example, the HD Tune Pro and HDDScan utilities or diagnostic utilities from hard drive manufacturers, however, these utilities only work with their own hard drive models, and therefore we will not consider them.
When using such solutions, there is a risk of damaging data on the scanned disk. On the one hand, if the drive really turns out to be faulty, anything can happen to the information on the disk during scanning. On the other hand, we cannot exclude incorrect actions on the part of the user who mistakenly starts scanning in write mode, during which data from the hard drive is erased sector by sector with a certain signature, and based on the speed of this process, a conclusion is drawn about the state of the hard drive. Therefore, compliance with certain precautionary rules is absolutely necessary: before launching the utility, you need to create a backup copy of the information and during the test, act strictly according to the instructions of the developer of the relevant software. To get more accurate results, before scanning, it is better to close all active applications and unload possible background processes. In addition, you should keep in mind that if you need to test the system HDD, you need to boot from a flash drive and start the scanning process from it, or completely remove the hard drive and connect it to another computer from which you can start testing the disk.
As an example, using HD Tune Pro, we will check the surface of the HDD for bad sectors, which did not inspire confidence in the Crystal Disk Info utility above. In this program, to start the scanning process, just select the desired disk, activate the tab Error Scan and click on the button Start. After this, the utility will begin sequential scanning of the disk, reading sector by sector and marking sectors on the disk map with multi-colored squares. The color of the squares, depending on the situation, can be green (normal sectors) or red (bad blocks) or will have some shade intermediate between these colors. As we see from Fig. 10, in our case the utility did not find full-fledged bad blocks, but nevertheless there is a significant number of sectors with one or another read delay (judging by their color). In addition to this, in the middle part of the disk there is a small block of sectors, the color of which is close to red - these sectors have not yet been recognized as bad by the utility, but they are already close to this and will move into the bad category in the very near future.

Rice. 10. Scanning the surface for bad sectors in HD Tune Pro
Testing a media for bad sectors in the HDDScan program is more difficult and even more dangerous, since if the mode is incorrectly selected, the information on the disk will be irretrievably lost. The first step to start scanning is to create a new task by clicking on the button New Task and selecting the command from the list Suface Tests. Then you need to make sure that the mode is selected Read- this mode is installed by default and when used, the hard disk surface is tested by reading (that is, without deleting data). After this press the button Add Test(Fig. 11) and double-click on the created task RD-Read. Now in the window that opens you can observe the disk scanning process on a graph (Graph) or on a map (Map) - fig. 12. Upon completion of the process, we will get approximately the same results as those demonstrated above by the HD Tune Pro utility, but with a clearer interpretation: there are no bad sectors (they are marked in blue), but there are three sectors with a response time of more than 500 ms (marked in red color), which pose a real danger. As for the six orange sectors (response time from 150 to 500 ms), this can be considered within normal limits, since such a response delay is often caused by temporary interference in the form, for example, of running background programs.

Rice. 11. Running disk testing in HDDScan program

Rice. 12. Results of disk scanning in Read mode using HDDScan
In addition, it should be noted that if there are a small number of bad blocks, you can try to improve the condition of the hard drive by removing bad sectors by scanning the disk surface in linear recording mode (Erase) using the HDDScan program. After such an operation, the disk can still be used for some time, but, of course, not as a system disk. However, you should not hope for a miracle, since the HDD has already begun to crumble, and there are no guarantees that in the near future the number of defects will not increase and the drive will not completely fail.
Programs for S.M.A.R.T. monitoring and HDD testing
HD Tune Pro 5.00 and HD Tune 2.55
Developer: EFD Software
Distribution size: HD Tune Pro - 1.5 MB; HD Tune - 628 KB
Work under control: Windows XP/Server 2003/Vista/7
Distribution method: HD Tune Pro - shareware (15-day demo version); HD Tune - freeware (http://www.hdtune.com/download.html)
Price: HD Tune Pro - $34.95; HD Tune - free (for non-commercial use only)
HD Tune is a convenient utility for diagnosing and testing HDD/SSD (see table), as well as memory cards, USB drives and a number of other data storage devices. The program displays detailed information about the drive (firmware version, serial number, disk capacity, buffer size and data transfer mode) and allows you to set the device status using S.M.A.R.T data. and temperature monitoring. In addition, it can be used to test the disk surface for errors and evaluate the device's performance by running a series of tests (sequential and random data read/write speed tests, file performance test, cache test and a number of Extra tests). The utility can also be used to configure AAM and securely delete data. The program is presented in two editions: commercial HD Tune Pro and free lightweight HD Tune. In the HD Tune edition, you can only view detailed information about the disk and the S.M.A.R.T. attribute table, as well as scan the disk for errors and test for speed in read mode (Low level benchmark - read).
The Health tab is responsible for monitoring S.M.A.R.T. attributes in the program - data from sensors is read after a set period of time, the results are displayed in a table. For any attribute, you can view the history of its changes in numerical form and on a graph. Monitoring data is automatically recorded in the log, but no user notifications are provided for critical changes in parameters.
As for scanning the disk surface for bad sectors, the tab is responsible for this operation Error Scan. Scanning can be quick (Quick scan) and deep - with a quick scan, not the entire disk is scanned, but only some part of it (the scanning area is determined through the Start and End fields). Damaged sectors are displayed on the disk map as red blocks.
HDDScan 3.3
Developer: Artem Rubtsov
Distribution size: 3.64 MB
Work under control: Windows 2000(SP4)/XP(SP2/SP3)/Server 2003/Vista/7
Distribution method: freeware (http://hddscan.com/download/HDDScan-3.3.zip)
Price: for free
HDDScan is a utility for low-level diagnostics of hard drives, solid-state drives and Flash drives with a USB interface. The main purpose of this program is to test disks for the presence of bad blocks and bad sectors. The utility can also be used to view the contents of S.M.A.R.T., monitor temperature and change some hard drive settings: noise management (AAM), power management (APM), forced start/stop of the drive spindle, etc. The program works without installation and can be launched from portable media, for example flash drives.
HDDScan displays S.M.A.R.T. attributes and temperature monitoring on demand. S.M.A.R.T report contains information about the performance and “health” of the drive in the form of a standard attribute table; the temperature of the drive is displayed in the system tray and in a special information window. Reports can be printed or saved as an MHT file. S.M.A.R.T. tests are possible.
The disk surface is checked in one of four modes: Verify (linear verification mode), Read (linear reading), Erase (linear writing) and Butterfly Read (Butterfly reading mode). To check a disk for the presence of bad blocks, a test in Read mode is usually used, which tests the surface without deleting data (the conclusion about the condition of the drive is made based on the speed of sector-by-sector data reading). When testing in linear recording mode (Erase), the information on the disk is overwritten, but this test can somewhat heal the disk, ridding it of bad sectors. In any of the modes, you can test the entire disk or a specific fragment of it (the scanning area is determined by indicating the initial and final logical sectors - Start LBA and End LBA, respectively). Test results are presented in the form of a report (Report tab) and displayed on a Graph and a disk map (Map), indicating, among other things, the number of bad sectors (Bads) and sectors whose response time during testing took more than 500 ms (marked in red ).
Hard Drive Inspector 4.13
Developer: AltrixSoft
Distribution size: 2.64 MB
Work under control: Windows 2000/XP/2003 Server/Vista/7
Distribution method: shareware (14-day demo version - http://www.altrixsoft.com/ru/download/)
Price: Hard Drive Inspector Professional - 600 rub.; Hard Drive Inspector for Notebooks - 800 rub.
Hard Drive Inspector is a convenient solution for S.M.A.R.T. monitoring of external and internal HDDs. Currently, the program is offered on the market in two editions: the basic Hard Drive Inspector Professional and the portable Hard Drive Inspector for Notebooks; the latter includes all the functionality of the Professional version, and at the same time takes into account the specifics of monitoring laptop hard drives. Theoretically, there is also an SSD version, but it is distributed only in OEM supplies.
The program provides automatic checking of S.M.A.R.T. attributes at specified intervals and, upon completion, issues its verdict on the condition of the drive, displaying the values of certain conditional indicators: “reliability”, “performance” and “no errors” along with a numerical temperature value and a temperature diagram. Technical data about the disk model, its capacity, total free space and operating time in hours (days) is also provided. In advanced mode, you can view information about disk parameters (buffer size, firmware name, etc.) and the S.M.A.R.T attribute table. There are various options for informing the user in the event of critical changes on the disk. Additionally, the utility can be used to reduce the noise level produced by hard drives and reduce HDD power consumption.
HDDlife 4.0
Developer: BinarySense Ltd
Distribution size: 8.45 MB
Work under control: Windows 2000/XP/2003/Vista/7/8
Distribution method: shareware (15-day demo version - http://hddlife.ru/rus/downloads.html)
Price: HDDLife - free; HDDLife Pro - 300 rub.; HDDlife for Notebooks - 500 rub.
HDDLife is a simple utility designed to monitor the status of hard drives and SSDs (from version 4.0). The program is presented in three editions: free HDDLife and two commercial ones - basic HDDLife Pro and portable HDDlife for Notebooks.
The utility monitors S.M.A.R.T. attributes and temperature at specified intervals and, based on the analysis results, issues a compact report on the condition of the disk indicating technical data about the disk model and its capacity, operating time, temperature, and also displays the conditional percentage of its health and performance, which allows Even beginners can navigate the situation. More experienced users can additionally look at the table of S.M.A.R.T. attributes. In case of problems with the hard drive, it is possible to configure notifications; You can configure the program so that if the disk is in normal condition, the scan results are not displayed. It is possible to control the HDD noise level and power consumption.
CrystalDiskInfo 5.4.2
Developer: Hiyohiyo
Distribution size: 1.79 MB
Work under control: Windows XP/2003/Vista/2008/7/8/2012
Distribution method: freeware (http://crystalmark.info/download/index-e.html)
Price: for free
CrystalDiskInfo is a simple utility for S.M.A.R.T. monitoring the status of hard drives (including many external HDDs) and SSDs. Despite being free, the program has all the necessary functionality to monitor the status of disks.
Disk monitoring is performed automatically after a specified number of minutes or on demand. At the end of the test, the temperature of the monitored devices is displayed in the system tray; detailed information about the HDD indicating the values of S.M.A.R.T. parameters, temperature and the program’s verdict on the state of the devices is available in the main window of the utility. There is functionality for setting threshold values for some parameters and automatically notifying the user if they are exceeded. Noise level management (AAM) and power management (APM) are possible.
Unfortunately, a considerable part of modern HDDs work normally for a little more than a year, then various kinds of problems begin, which over time can lead to data loss. This prospect can be completely avoided if you carefully monitor the condition of the hard drive, for example, using the utilities discussed in the article. However, you should also not forget about regular backup of valuable data, since monitoring utilities, as a rule, successfully predict disk failure due to mechanical faults (according to Seagate statistics, about 60% of HDDs fail due to mechanical components), but they are not able to predict the death of a drive due to problems with the electronic components of the disk.
What is a SMART HDD (hard drive) and what needs to be done if the computer displays the message “smart status bad backup and replace”.All modern drives of recent years from absolutely any manufacturer have a SMART system (self-monitoring, analysis and reporting technology) of the hard drive, which is very closely related to the operation of the drive.
Modern SMART technologies carry out: monitoring various parameters of the disk condition, scanning the surface of the hard disk with further automatic replacement of unreadable sectors and recording them in the error-log, the so-called. a list where the numbers of these sectors are stored in the form of a table, periodic rescanning of “unreliable” sectors from the error-log and, if the system determines that this sector is healthy, it excludes it from this list and it becomes available on the surface for user information (but is also marked for further re-checking during the next scanning of the surface), or if the sector is not read several times in a row and is not rewritten, then it is sent to the next defect list, which is named differently by different manufacturers, but has the same purpose - this sheet is like would be an intermediary between the error-log table and the final G-list, where the defect will already be entered into the G-list forever and will be displayed in SMART, in the line current pending sectors/offline UNC sectors.
From the current pending status, after the next re-check for survivability, the damaged sector, if read/write fails, is finally sent to the reassigned status and remains there. The disk no longer uses it in further operation and does not retest it for reading/writing.
In the reallocated sector count line the value changes from N to N+1.
If the drive already has serious damage, then when you boot the computer, the following message may appear: “smart status bad backup and replace.” This means that the SMART status of the hard drive has changed from the GOOD state to the BAD state, the disk has at least BAD blocks, and the disk condition continues to deteriorate. The user is recommended to save his data if it is still readable and replace the hard drive with a new one.
SMART LOOKS LIKE THIS:
Displayed as a table with the following columns:
ID – PARAMETER IDENTIFICATION NUMBER
Name – parameter name displayed by the program
VAL – NORMALIZED PARAMETER VALUE (NORMALIZED MEANS, IN THIS CASE, THAT THE INTERNAL (RAW) PARAMETER VALUE IS CONVERTED ACCORDING TO A CERTAIN ALGORITHM FOR A MORE CONVENIENT AND UNDERSTANDABLE VIEWING OF THE VALUE. E.G., VNU THE FRICTION PARAMETER ALWAYS INCREASES AND CAN ACCEPT A VALUE OF SEVERAL THOUSAND UNITS, AND THE DISPLAYED VALUE CHANGES FROM 100 TO 0 AND DISPLAYS THE INTERNAL PARAMETER CHANGE RANGE TO THE DISPLAYED RANGE AND THERE IS, IN THIS CASE, NORMALIZATION)
Wrst – worst parameter value for a period of time
Thresh – threshold value, upon reaching which it is recommended to replace the disk
LET'S CONSIDER WHAT PARAMETERS THERE ARE IN THE SMART SYSTEM. THE SET OF PARAMETERS TO BE MONITORED DEPENDS ON THE DISK MANUFACTURER AND NOT ALL OF THE LISTED WILL BE PRESENT IN YOUR CASE.
SMART attributes:
1 Raw read error rate - number of errors when reading sectors from plates.
2 Throughput Performance - overall disk performance in relative units.
3 Spin-up time - time to spin the plates from zero to the nominal rotation speed in milliseconds
4 Number of spin-up times - number of spin-up/stop cycles of the plates; reflects the mechanical life of the drive due to the limited number of start/stop cycles.
5 Reallocated sector count - the parameter reflects the number of spare sectors; when the disk finds a read/write/verify error, it reassigns the bad sector to a good one from the spare area; the normalized value of the attribute decreases as spare sectors decrease; The RAW value shows the number of assigned sectors, which should normally be zero; on SSDRAW the value shows the number of bad flash memory blocks.
6 Read Channel Margin - this attribute is not used in modern drives.
7 Seek error rate - number of magnetic head positioning errors.
8 Seek Time Performance - average speed of magnetic head drive positioning to the specified sector; in SSD this parameter is not used
9 Power-on time - the expected lifetime of the disk, based on the time spent in the power-on state; the normalized value decreases from 100 to 0, related to disk resource; a decrease in this parameter indirectly indicates the state of the disk mechanics
10 Spin-up retries - the number of attempts to spin the plates, provided that the first attempt was unsuccessful; is counted from the moment of use; not used on SSD
12 Start/stop count - expected lifetime based on the number of starts/stops of the plates; each disk has a limited number of starts/stops, the parameter is reduced from 100 to 0; RAW value shows the number of on/off switches
13 Soft Read Error Rate - some manufacturers describe this parameter as indicating the number of errors not recovered by ECC, while others, on the contrary, are recovered
100 Erase/Program Cycles - the total number of read/write cycles for the entire flash memory over its entire service life; SSD has a limit on the number of read/write cycles, the specific value depends on the type and manufacturer of flash memory chips
103 Translation Table Rebuild - number of events to rebuild the internal table of block addresses when it is damaged and restored; RAW value shows the current amount of event data
170 Reserved Block Count - describes the state of the reserve block pool in the SSD, shows the percentage of remaining blocks; The RAW value sometimes shows the number of reserved blocks used
171 Program Fail Count - number of times a flash memory block failed to be written
172 Erase Fail Count - number of times a flash memory block erase operation failed
173 Wear Leveller Worst Case Erase Count - maximum number of erase operations performed on a flash memory block
178 Used Reserved Block Count - describes the state of the reserve block pool in the SSD, shows the percentage of remaining blocks; The RAW value sometimes shows the number of reserved blocks used
180 Unused Reserved Block Count - describes the state of the reserve block pool in the SSD, shows the percentage of remaining blocks; The RAW value sometimes shows the number of unused reserve blocks
183 SATA Downshifts - shows how often it was necessary to reduce the SATA transfer speed (from 6Gb/s to 3Gb/s or 1.5Gb/s) for successful data transfer; when the attribute value decreases, the cable should be replaced
184 End-to-End error - number of errors that occurred in the disk buffer; part of HP SMART IV technology; may indicate a faulty disk RAM buffer
185 Head Stability - there is no reliable information on the attribute
186 Induced Op-Vibration Detection - there is no reliable information on the attribute
187 Reported UNC error - number of uncorrected read errors
188 Command timeout - number of commands not executed by the disk due to timeout
189 High Fly writes - number of write errors caused by incorrect flight height of the magnetic head above the surface
190 Airflow temperature - air temperature inside the HDD hermetic block
191 G-Sense Errors - indicates how many times the drive interrupted operation due to shock or vibration
192 power-off retract cycles - the number of unexpected power outages when it was lost before the command to turn off the disk was received; HDD service life during unexpected shutdown is significantly shorter than during normal shutdown; SSDs have a risk of losing the internal state table if there is an unexpected power loss
193 load/unload cycles - number of BMG movements between the parking zone and the data zone; the value decreases from 100 to 0, raw contains the current number of movements
194 hda temperature - temperature of the magnetic head unit
195 hardware ecc recovered - number of read errors corrected by error correction code
196 reallocation events - the total number of sector reassignments, includes both off-line scanning and normal work
197 current pending sectors - number of unstable sectors awaiting recheck and possibly reassignment
198 offline scan unc sectors - the number of bad sectors found by the disk during background self-scanning; deterioration of this parameter indicates rapid degradation of the surface
199 ultra dma crc errors - number of errors when transferring data between the disk and the motherboard; if this parameter deteriorates, it is worth replacing the cable
200 write error rate - frequency of errors when writing
202 data address mark errors - number of errors when searching for the requested sector
203 run out cancel - number of errors caused by an incorrect checksum when trying to correct an error
204 soft ecc corrections - number of errors corrected by the correction code
206 flying height - deviation of the flight height of the head above the surface relative to the optimal value; if the head is too low it can damage the surface, if too high it increases the number of reading errors
207 spin high current - the amount of current required to spin the plates
209 offline seek performance - performance of the search subsystem when performing off-line scanning
220 disk shift - the distance by which the plate pack has shifted relative to the theoretical position as a result of mechanical damage or overheating
227 torque amplification count - shows how many times it was necessary to apply increased current to spin up the plates
230 gmr head amplitude - vibration amplitude of the bmg heads
233 media wearout indicator - remaining memory resource in ssd
240 head flying hours - time spent by the heads in the user data zone; the value decreases, usually from 100 to 0
241 total lbas written - the number of 512-byte blocks written over the entire life of the device
242 total lbas read - the number of 512-byte blocks read over the entire life of the device
250 read error retry rate
The difficulty in interpreting smart values is that there is no single standard for the quantity, type, values, or units of measurement of the monitored parameters. Therefore, the implementation of smart always depends on the specific manufacturer. Everyone does normalization of raw values into attribute indicators in their own way, and the result is a check status of smart good or bad. therefore, a reliable conclusion about the condition of the disk can only be made by checking its surface with some diagnostic program. but if you need to quickly assess the condition of the disk and possible problems, you need to pay attention to several basic, most informative attributes.
The most important attributes of smart:
5 reallocated sectors count - number of reassigned sectors; An increase in the value of this attribute indicates a deterioration in the condition of the disk surface
The latest drives are represented by intelligent devices that can analyze their status and promptly inform the user about problems. To achieve this, the hardware includes the original S.M.A.R.T. option.

Purpose of SMART technology.
The lion's share of disk drives in recent years operates using S.M.A.R.T. technology. The combination stands for self-monitoring, analysis and reporting technology , which in Russian sounds like a mechanism of self-control, analysis and reporting. Its first developments were released in 1995 and since then the technology has been constantly improved.
From the moment of production, the disk drive begins to read its current state, defining it using special parameters or attributes. They are located, accessible only by the built-in program. You can view the parameters using separate software, most often represented by utilities from the developers of a specific hard drive. Through them, inputs are sent to the drive, after which information about the current state of the disk will appear in the statistics log.
During the operation of the drive, the data presented within the parameters of the values are constantly changing. The parameters go from maximum values, guaranteeing high performance and efficiency, to minimum values, associated with a high probability of drive failure.
All attributes presented within the framework of S.M.A.R.T technology have a digital identifier. As a rule, it is common for drives of different versions, but there are exceptions. In this regard, the number 7 stands out, demonstrating errors in the placement of heads on the disk surface. For digital identifier is not relevant. Unlike 7, the number 9, which shows the total period of direct operation of the drive over the period of use, is supported by all types of HDD and SSD drives.
The structure of the parameters is represented by several fields demonstrating the state of the disk and its partitions during a specific period. Utilities designed for reading information display the following parameters on the screen:
- ID – identification number
- name – attribute name
- VAL – its current state
- Wrst – the worst indicator for the period of operation
- Thresh – minimum performance threshold
S.M.A.R.T indicators
There are several most common parameters. With rare exceptions, they combine drives from most manufacturers, so:
- Raw Read Error Rate – indicator of the number of reading errors
- Throughput Performance - operational efficiency. Its decrease indicates the need for replacement
- Spin Up Time – period of deployment of the drive into working state. An increase in the parameter demonstrates wear and tear or lack of nutrition
- Start/Stop Count – an indicator of the number of times the disk deploys, which is initially limited by its mechanical structure
- Reallocated Sectors Count – the attribute reflects the number of spare sectors. Information is redirected there in case of problems. Ideally, the number of such actions should be 0
- Read Channel Margin – channel reserve. Nowadays, drives do without it
- Seek Error Rate – Reflects the mechanical condition of the drive, including, among other things, demonstrating excessive vibration and overheating
- Seek Time Performance – level of operational capabilities, relevant only for HDDs
- Power-on Time – forecast of the duration of operation of the drive based on the period of operation. The maximum indicators are 100 and decrease to 0 over time
- Spin-Up Retry Count – number of duplicate launch operations. Their increase indicates errors in the mechanical structure
These and other attributes with a red background indicate that the drive is in critical condition, which suggests an imminent failure. There is no specific standard that combines parameter indicators from different manufacturers. In each case, normal values are individual, reflected in the form of a background or status, where
- Good - good indicator
- Bad is a bad indicator.
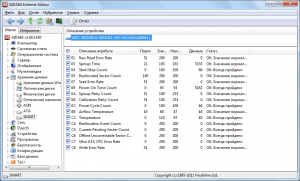

Along with the attributes already mentioned, attention should be paid to such parameters as:
- Recalibration Retries – number of takes during recalibration. Their increase indicates a mechanical problem
- End-to-End error – Disadvantages of exchange operations
- Reported UNC Errors - problems that can be resolved using hardware
- G-sense error rate – the number of mechanical impacts on the disk. Detects inaccurate installation, collisions
- Reallocation Event Count – a general indicator of information redirection operations. Records successful and unsuccessful operations
- Current Pending Sector Count – number of potential drive sections to be replaced
- Uncorrectable Sector Count – number of bad sectors that cannot be restored
- UltraDMA CRC Error Count – problems with data redirection between the drive and PC
S.M.A.R.T check
S.M.A.R.T parameters are checked using special utilities from hard drive manufacturers. There are also universal programs for testing and checking disks. Among them are udisks, smartctl, hddscan, CrystalDiskInfo, Victoria, using which the user can assess the condition of the hard drive. In some cases, namely when working with RAID controllers, it is almost impossible to obtain disk attributes.


The minimum level of diagnostics is supported at the BIOS level. If the S.M.A.R.T. diagnostic mode is enabled, then if there are critical attribute values, the BIOS will not allow the operating system to boot.
So, when testing the condition of the hard drive, first of all, attention is paid to the specified S.M.A.R.T parameters. The main purpose of the technology is to predict the failure of a hard drive. If indicators deviate dangerously from the norm, it makes sense to transfer important information to other media.
And, most importantly, even if S.MA.R.T. there are no errors and everything is fine, this is not a guarantee that the disk will not break, so .







